Hash Table(雜湊表)是儲存Key和Value的的資料結構。我們可以透過關鍵字映射到一個數組中一個位置來實現對資料的快速訪問。key會是唯一的,可以用來查找對應的value。
Hash Table 通常是通過Hash function實現的。Hash function通常把key映射到一個整數,這個整數就是該關鍵字在數組中的下標。當我們要查找某個key對應的value時,可以通過哈希函數計算出該key對應的下標,然後直接訪問該下標對應的value,這樣就可以快速的訪問。
Hash collision
當兩個不同的key對應到同一個value的話,那就有可能發生碰撞(Hash collision)。這在有大量資料的情況下有可能會發生,所以在使用Hash Table的時候可能必須要適當地設計Hash function和處理Hash collision等問題。
時間複雜度
Hash Table因為是透過關鍵字映射到一個數組中一個位置,所以時間複雜度通常為 O(n)。
Hash Set和Hash Map
Hash 又分成Hash Set和Hash Hash Map。
- Hash Set為一個集合,可以存不同的對象,但不允許重複的元素,除了python和c++,在其他語言中也是可以被實現的。
- Hash Map是一個映射,key對應value的關係,可允許多個key對應到相同的value,除了python和c++,在其他語言中也是可以被實現的。
以下是我最近在node.ls中寫的一個Hash Map的例子。

在python中的用法
- Hash Set hashset = set()
- 新增元素
- hashset.add(1000)
- 檢查元素是否存在
- if 1000 in hashset:
- 刪除元素
- hashset.remove(1000)
- 新增元素
- Hash Map hashmap = { }
- 新增元素
- hashmap[‘key1’] = ‘value1’
- 檢查元素是否存在
- if ‘key1′ in hashmap:
- 刪除元素
- del hashmap[‘key1’]
- 新增元素
什麼時候適合用Hash Table?
- 儲存
- 找重複
- 計算數量
1. 儲存
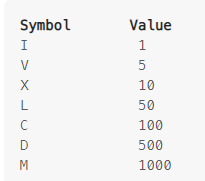
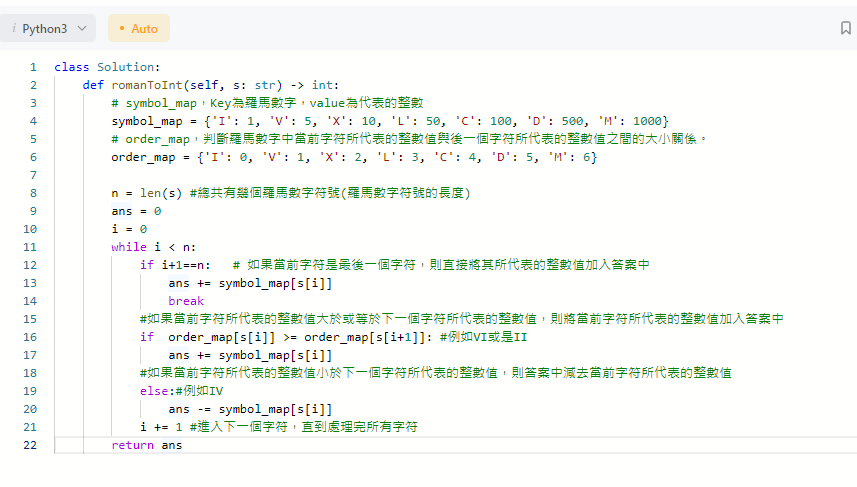
以leetcode的13. Roman to Integer 來說,需要做的是把給定的羅馬符號轉為整數,
例如”LVIII”會輸出58這個整數。
| I | 1 | 1 | |
| II | 2 | 1+1 | 下一個跟我一樣 (加) |
| III | 3 | 1+1+1 | 下一個跟我一樣 (加) |
| IV | 4 | 5-1 | 下一個比我大 (減) |
| V | 5 | 5 | |
| VI | 6 | 5+1 | 下一個比我小 (加) |
| VII | 7 | 5+2 | 下一個跟我一樣 (加) |
| VIII | 8 | 5+3 | 下一個跟我一樣 (加) |
| IX | 9 | 10-1 | 下一個比我大 (減) |
| X | 10 | 10 |
2. 找重複
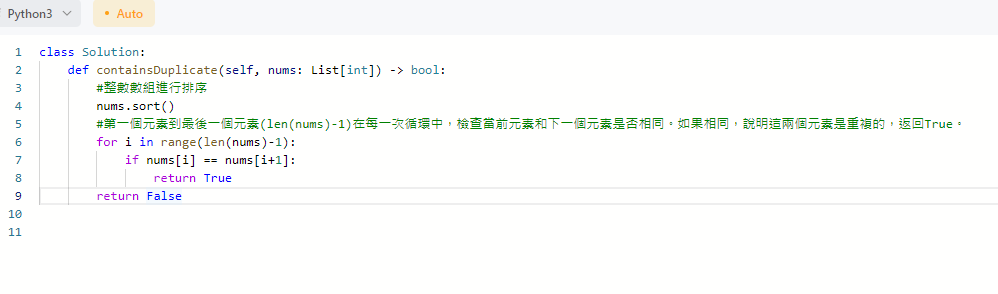
以leetcode的217. Contains Duplicate 來說,若是array中出現相同的兩個同樣數字的話就印出true,沒相同的話印出false。
- 方法一
先排序再跟下一元素做比較的算法,這種時間複雜度較高,因為是排序再比較所以
時間複度是O(nlogn)
空間複雜度O(1)
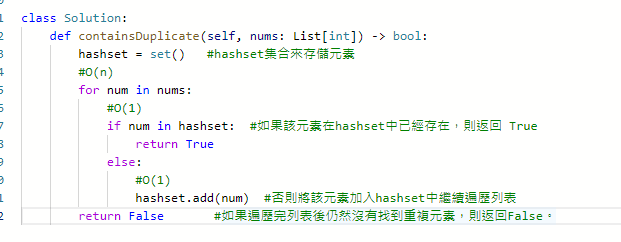
- 方法二
利用hashset = set() 這個hashset集合來存儲元素,檢查元素是否存在於hashset集合,若是不存在就增加到集合中繼續比對,直到找到相同元素,若比到最後都沒發現相同的話回傳False。
時間複雜度O(n)
空間複雜度O(n)
- 方法三
利用Python 的內建函數set()將列表轉化為一個集合。集合是一種無序的且元素不重複的集合,因此 set(nums)可以創建一個不包含重複元素的集合。
主要作法是檢查集合和原本的List的長度是否相等。如果相等,就代表示沒有重複元素,如果不相等,表示有重複元素(重複元素會在新創建的集合被刪除)。
時間複雜度O(n)
空間複雜度O(n)

3. 計算數量
以leetcode的438. Find All Anagrams in a String來說,在一個字串s中找到所有與另一個字串p相同的字符排列,並返回這些字符排列在s中開始的位置
用兩個字典 s_counter和 p_counter來記錄s和p中每個字元出現的次數,然後一個一個從 s 的頭開始往後移動,每次移動一個位置,就從 s_counter中減去前一個字元的出現次數,再加上新的一個字元的出現次數,然後比對 s_counter和 p_counter是否相同。如果相同,就將當前位置加入答案陣列 ans中。
時間複雜度O(n)
空間複雜度O(1)

collections.Counter()
collections.Counter()這個Python的內建容器可計算元素出現的次數,它會返回一個字典,其中每個key表示元素,key對應的value表示該元素出現的次數。
import collections
p = "abc"
p_counter = collections.Counter()
for c in p:
p_counter.update(c)
print(p_counter)Counter({'a': 1, 'b': 1, 'c': 1})若是用在剛剛的leetcode的438. Find All Anagrams in a String的話,可以把p_counter和s_counter改成collections.Counter()
